
Kubernetes | Présentation & installation via Minikube sur Ubuntu 19.04
Aujourd’hui un article assez conséquent où l’on va présenter Kubernetes ainsi que décrire son installation via l’utilitaire Minikube le tout sur une Ubuntu 19.04 !
Comme dit en préface nous allons donc voir ensemble ce qu’est Kubernetes, expliquer ses bases puis nous verrons comment installer l’utilitaire Minikube qui permet de créer un cluster à une seule node.
Sans plus tarder, commençons !
*Il est fortement recommandé d’avoir des bases en Docker pour comprendre cet article, si les termes “Docker, conteneurs, hub” et autre ne vous sont pas familier, je vous renvoi à mon précédent article introduisant Docker.
I) Kubernetes, c’est quoi ?
Kubernetes est une plate-forme open-source extensible et portable pour la gestion de charges de travail (workloads) et des services conteneurisés. Elle favorise à la fois l’écriture de configuration déclarative (declarative configuration) et l’automatisation. C’est un large écosystème en rapide expansion. Les services, le support et les outils Kubernetes sont largement disponibles.
www.kubernetes.io
En des termes plus simples, Kubernetes est donc un orchestrateur de conteneurs (pas forcément que de Docker, mais nous allons surtout parler de Docker pour rester le plus simple possible) et permet donc de créer des clusters de haute-disponibilité pour déployer des applications mais aussi réaliser du monitoring, du provisioning ou encore gérer l’aspect réseau…
Pour la petite partie culture, Kubernetes (abrégé souvent k8s) a été développé initialement par Google qui l’a ensuite rendu OpenSource en 2014, et depuis le projet a pris beaucoup d’ampleur.
Si pour vous c’est toujours un peu flou, je vous conseille de rester encore un peu patient, des exemples et de la pratique seront présents un peu plus bas 😉
Bien, je vais maintenant rapidement vous décrire le fonctionnement de Kubernetes. Pourquoi rapidement ? Car vous allez vite vous rendre compte que -surtout pour un débutant- il y a pas mal de notions à retenir, et que je suis donc obligé de résumer un maximum certaines choses pour ne pas vous perdre au bout de quelques paragraphes 😁
A noter qu’en fin d’article je vous donnerai quelques liens d’autres blogs/vidéos/articles décrivant eux aussi k8s, histoire que vous puissiez en apprendre un peu plus par vous même aussi.
Un cluster Kubernetes fonctionne donc en deux parties :
- Un (ou plusieurs) serveurs Master : c’est le serveur qui gère le cluster, on lui donne des commandes qu’il va exécuter sur les serveurs workers ;
- Un (ou plusieurs) serveurs Worker : c’est le serveur qui va héberger les conteneurs Docker, et donc nos applications ;
Un Worker peut donc être une machine virtuelle, un serveur physique, un VPS chez un prestataire de Cloud… peut importe !
Différents processus vont donc tourner sur ces deux types de serveur :
- Master :
- kube-apiserver, permettant de rentrer des commandes qui vont être exécutées sur le cluster (via un dashboard web ou via CLI, par l’utilitaire kubectl) ;
- Etcd, sorte de “base de données”, ou plutôt d’espace de stockage où sont stockées les données nécessaires pour le bon fonctionnement de Kubernetes, comme les différentes configurations etc ;
- kube-controller-manager, permettant d’identifier les utilisateurs du cluster ;
- kube-scheduler, permettant de faire de la répartition de charges, c’est-à-dire par exemple migrer tel conteneur sur tel worker car l’actuel est saturé niveau charge ;
- Worker :
- kubelet, permettant de communiquer avec le Master ;
- kube-proxy, permettant d’exposer certains ports des conteneurs et donc de rendre disponible des services internes vers
l’extérieur, mais aussi de gérer des règles réseau ; - docker, et oui car mine de rien, il faut bien un environnement d’exécution pour ces fameux conteneurs ! On aurait pu aussi mettre “rkt” à la place mais comme dit en début d’article, nous allons nous contenter du plus simple ;
Bon, jusqu’ici ça va encore, rien de très compliqué non ? Aller, voilà un petit schéma histoire que vous puissiez mieux comprendre le tout !

"C'est quoi ça, les "Pods" là ?"
Hmmmm, on n’peut rien vous cacher décidément. Aller, j’avoue tout, vous allez encore devoir un peu vous accrocher car on va aborder la dernière grosse notion (promis !) pour bien cerner k8s ! Les objets, qui sont au nombre de quatre et que l’on va rapidement passer en revu.
L’objet Pod : Plus petit objet de k8s, il contient un conteneur (ou plusieurs, mais pour le moment gardez à l’esprit qu’un pod = un conteneur).
L’objet Deployment : on peut voir cela comme une “surcouche” au pod, c’est le deployment qui va gérer entre autre :
- Le nombre de réplicas de notre instance (combien de conteneurs doivent être lancés pour ce service ?) ;
- Le nom de l’image Docker utilisée ;
- Le ou les port(s) d’écoute ;
- Le ou les points de montage(s) et volume(s) ;
Pour certains connaisseurs, on peut voir les Deployments comme les Services de Docker Compose.
L’objet Service : C’est une autre surcouche (décidément…) qui va simplement se charger d’exposer le port utilisé par le ou les conteneurs sur un port du worker choisi aléatoirement entre 30000 & 32767. Par exemple, vous lancez un conteneur faisant tourner Apache, qui utilise donc le port 80, et bien le Service va vous permettre d’utiliser le port 32186 pour arriver sur le port 80 de votre conteneur Apache. Tout simplement !
L’objet Ingress : Il va permettre d’autoriser l’exposition du Service sur le port souhaité, et dans ce cas on parle de Règles Ingress. Je ne vais pas détailler trop cela pour le moment, car nous n’utiliserons cela que lorsque l’on devra réaliser du routage HTTP, faire du load-balancing, ou d’autres choses du genre.
Bien ! Pour terminer cette bonne grosse partie théorie et vous laisser un peu digérer, voici un petit schéma du site ineat-conseil qui décrit plutôt bien la notion d’objets :
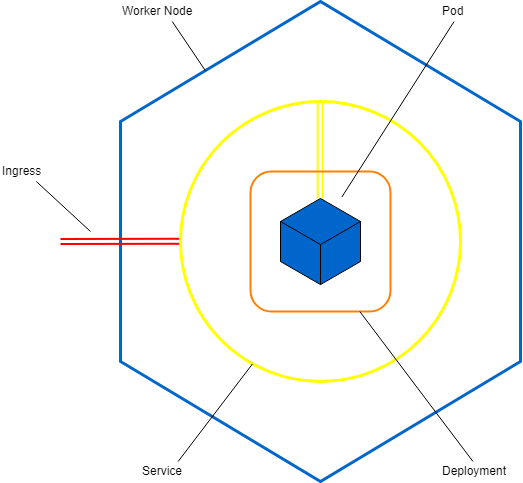
C’est désormais un peu plus clair non ? Si ce n’est pas encore le cas, ne vous en faites pas, ça viendra avec la pratique !
II) Et Minikube dans tout ça ?
Minikube est un utilitaire permettant de créer une machine virtuelle qui sera à la fois un master et un worker, et permettra donc de créer un cluster d’une seule node pour pouvoir nous exercer. Il n’est donc pas du tout destiné à la mise en production mais dès que l’on veut mettre un peu la main à la pâte on passe par lui !
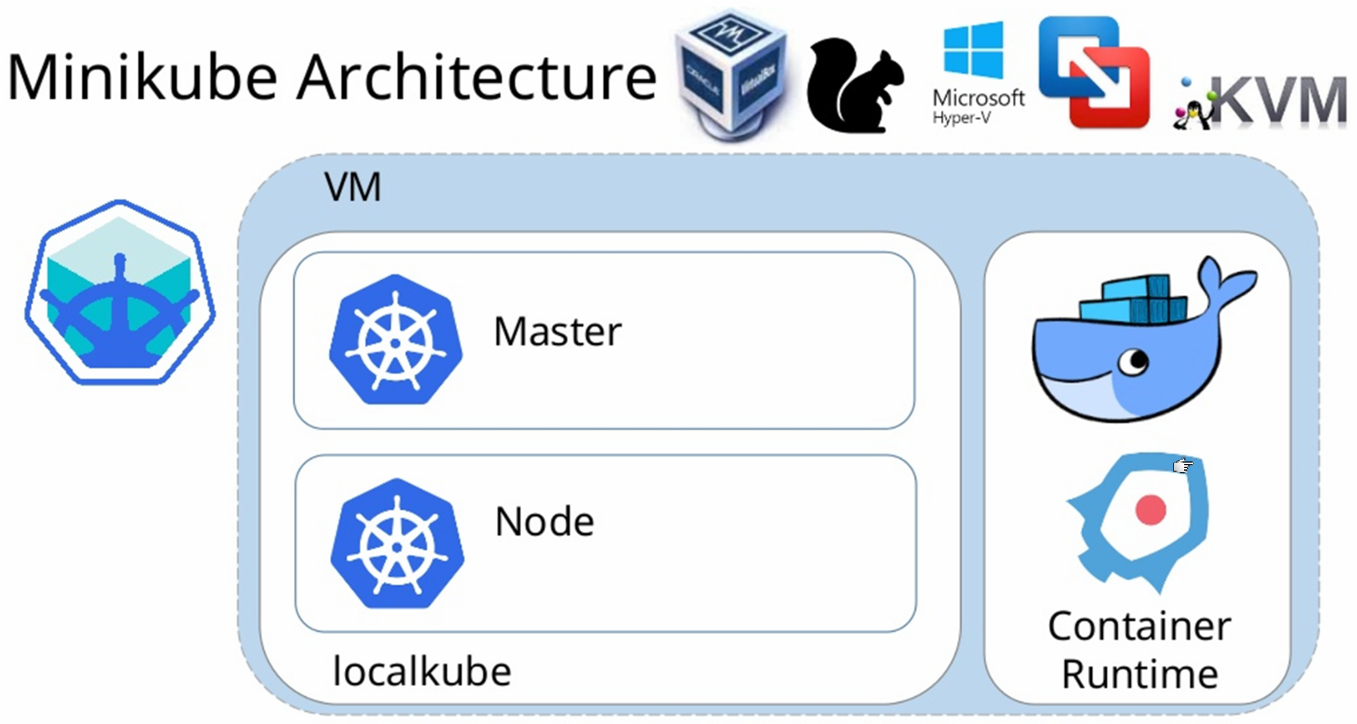
Concernant la création de la fameuse machine virtuelle, nous pouvons utiliser Hyper-V (Windows), VirtualBox (MacOS/Linux), ou bien encore l’exécuter en local complet sur notre machine, mais cela est déconseillé et il vous faudra une machine sous GNU/Linux pour réaliser cela.
III) Création de la VM Ubuntu 19.04
Après toutes explications, nous allons donc enfin pouvoir commencer à rentrer dans le vif du sujet ! Nous partirons donc sur une machine virtuelle Ubuntu avec l’hyperviseur VirtualBox qui sera installée sur cette dernière, il faut donc bien veiller à activer la virtualisation Intel-VT / AMD-V sur notre VM. Voici la configuration que j’ai choisie (un disque de taille moyenne, assez de mémoire vive pour lancer plusieurs dizaines de conteneurs, et un processeur un chouilla plus puissant que d’habitude) :
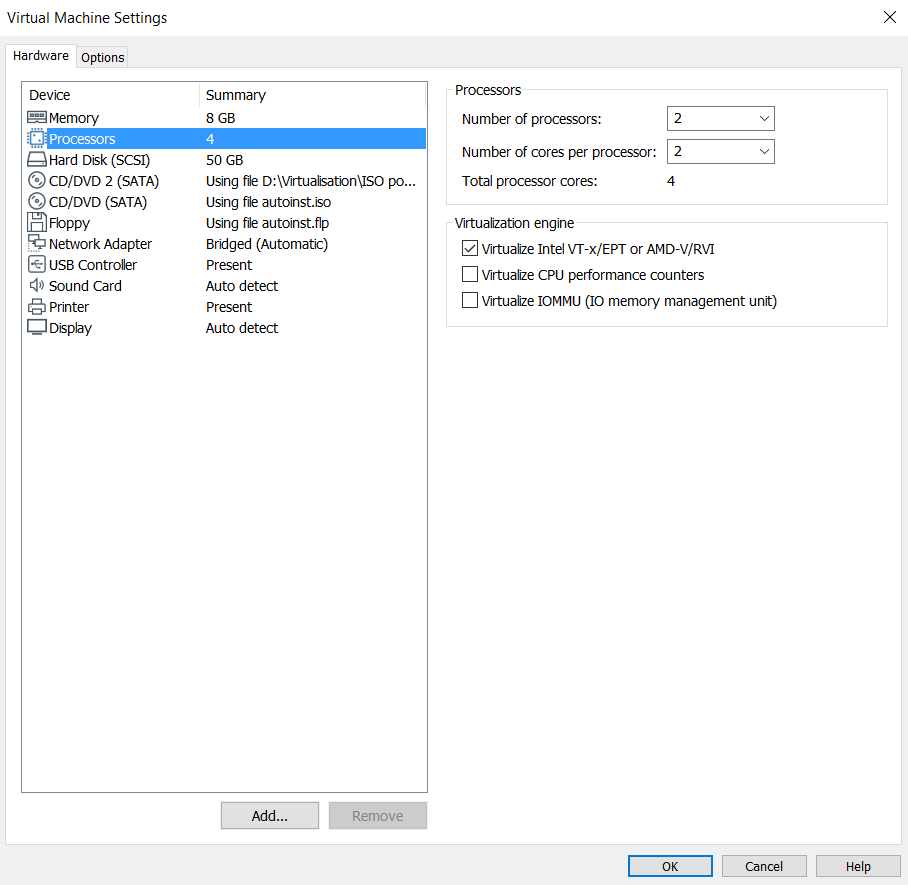
On démarre et on installe notre Ubuntu de manière classique.
Ensuite on met le système à jour (dépôts/paquets) et on installe les dépendances requises (il n’y a que apt-transport-https de réellement requis cela dit) :
sudo apt-get update && sudo apt-get upgrade -y
sudo apt-get install curl zip htop apt-transport-https -y
Une fois fait, on se doit d’installer un hyperviseur, car rappelez-vous ; Minikube va créer une machine virtuelle qui hébergera tout notre cluster, mais pour cela il faut donc que l’on installe un hyperviseur. Ici, on va se contenter du classique VirtualBox, qui fonctionne d’ailleurs aussi bien sous Window$/Mac/Linux :
sudo apt install virtualbox virtualbox-ext-pack -yEnsuite, on télécharge et on installe Minikube :
wget https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
chmod +x minikube-linux-amd64
sudo mv minikube-linux-amd64 /usr/local/bin/minikube
Et enfin, on installe l’utilitaire kubectl qui va donc nous permettre de gérer notre cluster en ligne de commandes (la CLI, c’est la vie comme on dit) :
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update && sudo apt-get install kubectl -y
Si tout est bon (et ça le sera) vous devriez obtenir ceci :

Et bien voilà ! On va pouvoir passer au démarrage de notre cluster, pas trop tôt !
III) Création du cluster via minikube
Ici rien de très compliqué, voici les différentes commandes de base à connaître :
- minikube start, pour démarrer le cluster ;
- minikube stop, pour stopper le cluster ;
- minikube delete, pour supprimer intégralement le cluster ;
- minikube ssh, pour accéder en SSH à la VM minikube (utilisateurs avancés seulement) ;
- minikube dashboard, pour démarrer le panel web ;
- minikube dashboard –url, pour afficher l’url du fameux dashboard ;
Bien, à partir de là on peut donc démarrer notre cluster (cela peut prendre quleques minutes la première fois, le temps de télécharger l’ISO etc) :
minikube start
Ensuite, on peut démarrer notre fameux dashboard :
minikube dashboard
Et bien voilà ! A partir de là, et jusqu’à ce que vous fassiez un minikube stop vous avez un cluster Kubernetes (d’une seule node) installé et fonctionnel ! Bravo !
Bon, on essaye de déployer un serveur Nginx pour voir un peu le déroulement ?
IV) Déploiement d’un conteneur Nginx
Pour vérifier que tout est bien fonctionnel, nous pouvons essayer de déployer un conteneur basé sur une image NGINX :
kubectl run website --image=nginx --port=80
Et si on se rend sur notre dashboard :

On voit que notre conteneur est bel et bien déployé ! On aurait pu aussi lister les déploiements via la commande suivante :
kubectl get deployments
Pour ensuite pouvoir atteindre notre conteneur depuis l’extérieur (car par défaut nos conteneurs sont isolés DANS le cluster !) il convient d’exposer le port à l’extérieur de celui-ci :
kubectl expose deployment website --type=NodePort
kubectl get services
Via la première commande nous allons donc exposer notre déploiement “website” sur le port 8080 en type “NodePort” et la seconde commande quant à elle ne sert qu’à vérifier les services actifs.
On peut ensuite ouvrir directement l’url de notre service website via la commande suivante :
minikube service website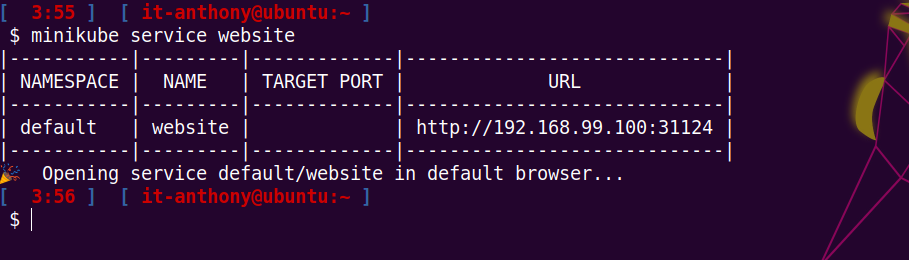
Et comme on peut le voir, it works !

A noter que si l’on désire simplement récupérer l’URL sans ouvrir celle-ci, on peut exécuter la commande suivante :
minikube service website --url=trueSi l’on retourne ensuite sur notre dashboard, dans Services, puis website et que l’on descend jusqu’à la partie Pods on peut afficher les logs de notre service en cliquant juste ici sur Journaux :

Et, tant qu’à faire, voici l’équivalent en ligne de commandes :
kubectl logs website-74dcdb9f88-5fm7x
Bien ! A ce stade, nous avons donc pu découvrir les bases de Kubernetes/Minikube, on a rapidement vu le dashboard, quelques lignes de commandes de l’utilitaire kubectl… est-ce qu’on essayerait pas de scaler notre service website avant la fin de cet article ? Allez, juste pour vous montrer rapidement alors !
V) Scaling de services via réplicas
Ici c’est un point très intéressant de Kubernetes, le scaling. Grossièrement, c’est le fait de pouvoir augmenter le nombre d’instances d’une application pour faire face à des pics de charges. Je m’explique :
- Ici, nous n’avons qu’un seul conteneur qui fait tourner notre site web NGINX, on va imaginer que celui-ci peut accueillir maximum 10 visiteurs.
- Si il y a soudainement 500 visiteurs, c’est la panique ! Sauf que l’on peut déployer rapidement et facilement des réplicas de notre instance NGINX, c’est-à-dire des “clones”, pour faire face à cette montée de charge.
- On appelle ça du scaling horizontal.
On va voir ça très rapidement ensemble, j’en parlerai bien plus longuement lors d’un prochain article. Pour lister les déploiements actuels :
kubectl get deployments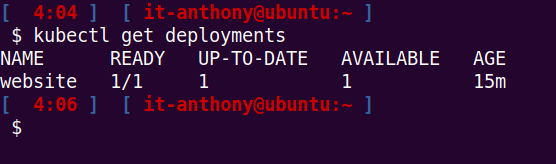
Ensuite, on exécute cette commande qui va donc créer 3 réplicas pour notre déploiement nommé website :
kubectl scale --replicas=3 deployment/website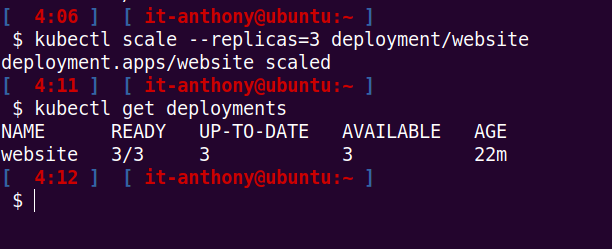
Et si l’on se rend sur notre dashboard :

Et à l’inverse, on peut “scaler” vers le bas :
kubectl scale --replicas=1 deployment/website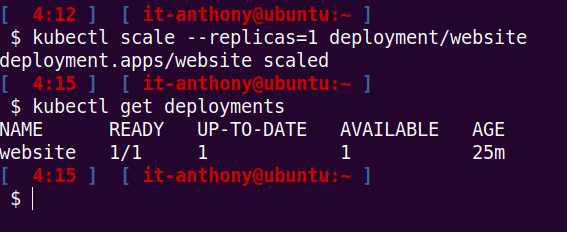
Tadaaaa ! En quelques secondes à peine on peut donc jongler avec le nombre de pods présents dans notre cluster ! Alors certes ici vous ne voyez peut être pas encore l’intérêt pour un simple serveur NGINX, mais dans le cas d’applications métiers ou de serveur d’API (NodeJS ou autre), cela peut devenir réellement intéressant 😉
Bref, cet article m’aura permis de résumer un peu mes connaissances actuelles en terme de k8s tout en me permettant de réaliser quelques labs sur le côté, et il n’est donc forcément pas parfait. Comme promis, voici quelques liens que je vous encourage vivement à consulter si vous souhaitez en apprendre davantage ou si vous n’avez pas saisi certaines notions présentées ici, car je suis encore loin d’être un expert en conteneurisation/orchestration :
- La formation Udemy de Mr Juggery, avec des vidéos très courtes et de bonne qualité -> https://www.udemy.com/course/la_plateforme_k8s/ ;
- Le blog de Valentin, qui date un peu mais où l’on peut aller piocher quelques notions supplémentaires -> https://blog.ouvrard.it/2016/12/13/kubernetes-de-zero/ ;
- PlayWithKubernetes, permettant de s’entraîner en ligne -> https://labs.play-with-k8s.com/ ;
- Et bien entendu, la documentation mi française/mi-anglaise de k8s -> https://kubernetes.io/fr/docs/tutorials/ ;
Une bonne journée/soirée à vous !



Laisser un commentaire